Augmented Qualitative Analysis (AQA) and Large Language Models (LLMs)
Conducting experiments in the automated labelling of topics generated using the Augmented Qualitative Analysis (AQA) process outlined in an earlier post has resulted in some observations that have some bearing on the use of Large Language Models (LLMs) in Soft OR/PSM practice.
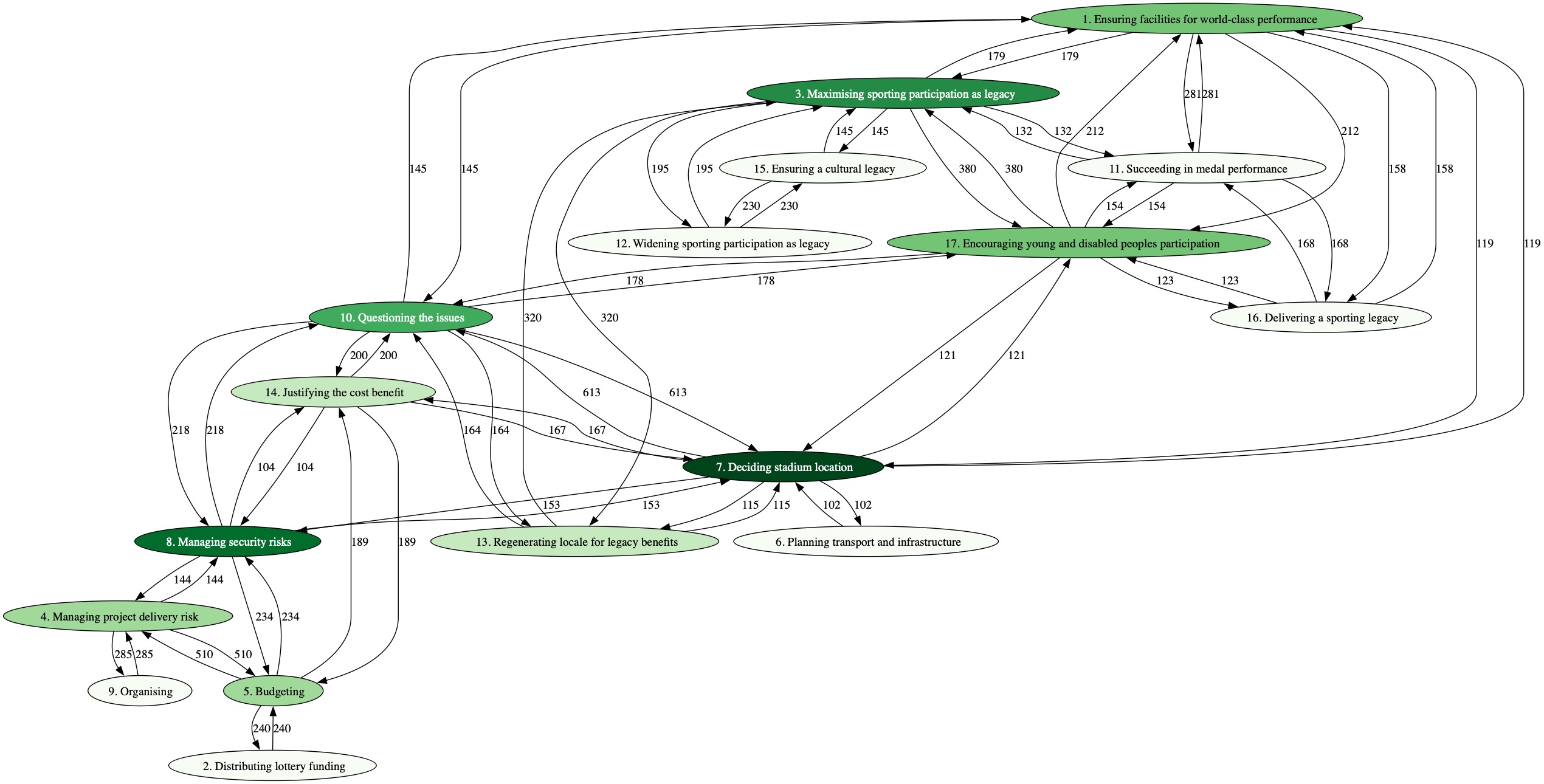
The starting point for AQA was the partial automation of some of the elements of qualitative analysis, which has resulted in the use of probabilistic topic models to code text in a corpus at the paragraph level and to produce maps of the interrelationship of concepts (qua topics). These maps of interrelationships can only be put forward for consideration as potentially causal links after the topics have been labelled. A map of topic X being linked to topic Y n times is only of statistical interest. We need meaning to be attached to the topics – ideally a process of consideration by a group that ‘owns’ the raw data – before we can produce a putative causal loop diagram (CLD).
To ground this technique in traditions of qualitative analysis would require the labelling of topics to proceed through an inductive process of inspecting the term lists and inspecting the text coded by the topics to build-up an understanding of what the topic means to the stakeholders (e.g., see Croidieu and Kim (2017)). This is a back-and-forth process that continues until all the topics have been labelled. The fact that the map can be updated with these topic labels in parallel provides an additional perspective on the understanding of the meaning of the topics.
With the advent of LLMs it is possible to feed the term lists and the example text coded by a topic – and even the map of interrelationships – into a tool like ChatGPT with the purpose of generating topic labels. However, experiments in doing this have produced disappointing results, despite extensive efforts in refining prompts. From the perspective of a qualitative researcher, the coding seems to be too much in the text, too in-vivo. Despite attempts to get the LLM to draw on the breadth of its training data there seemed little evidence of the sort of theorising from the data that is a key feature of qualitative analysis (Hannigan et al., 2019).
This is clearly a new area and other researchers have conducted experiments on precisely this point of prompt engineering e.g., see Barua, Widmer and Hitzler (2024). However, there is still the sense that a LLM is operating as nothing more than a ‘stochastic parrot’ (Bender et al., 2021). Further, coupling the outputs from a probabilistic topic model to a LLM are unlikely to generate the sort of management insight that is discussed by Hannigan et al. (2019); although the putative causal maps are likely to make sense to the participants in a group, and are statistically justified. Ultimately, the use of LLMs in a process of problem structuring is only ever going to be limited. Problematising is a human activity, it requires a felt-sense of a situation being problematic for an intent to intervene to emerge. Asking a LLM to feel something is a wayward expectation.
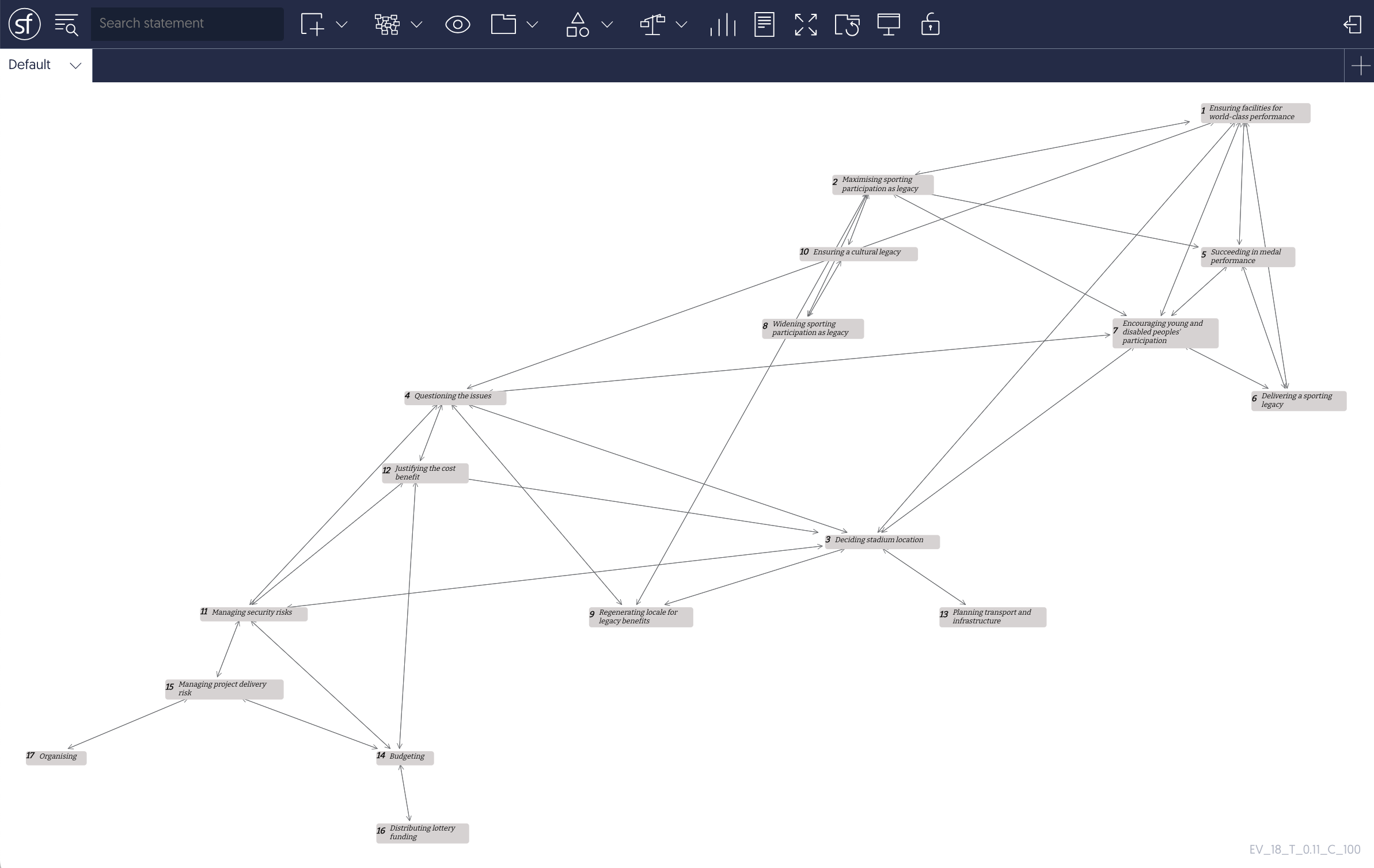
The recommendation here, for any group working with a large and potentially growing corpus of documents and in need of a technique that supports rapid problematisation, is to work with two Group Support Systems (GSS). The first presents an interactive means of exploring the probabilistic topic model (e.g., using pyLDAvis the topic model for the 2012 Olympics data set discussed in a previous post can be explored here) combined with a means of investigating the text as coded by the topic model i.e., selecting text that is coded by a specific topic and inductively generating a topic label that has meaning to the group. In effect, replicating some of the features of a Computer Aided Qualitative Data Analysis Software (CAQDAS). The fully labelled model can then be taken into a strategy-making workshop supported by the second GSS, in this case Strategyfinder.
The prospects of these two GSS merging into a single Problem Structuring Platform is the subject of my upcoming talk at OR66, see my previous post on AQA.
Barua, A., Widmer, C., & Hitzler, P. (2024). Concept Induction using LLMs: a user experiment for assessment. https://doi.org/10.48550/arXiv.2404.11875
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? FAccT 2021 – Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, https://doi.org/10.1145/3442188.3445922
Croidieu, G., & Kim, P. H. (2017). Labor of Love: Amateurs and Lay-expertise Legitimation in the Early U.S. Radio Field. Administrative Science Quarterly, 63(1), 1-42. https://doi.org/10.1177/0001839216686531
Hannigan, T. R., Haan, R. F. J., Vakili, K., Tchalian, H., Glaser, V. L., Wang, M. S., Kaplan, S., & Jennings, P. D. (2019). Topic modeling in management research: Rendering new theory from textual data. Academy of Management Annals, 13(2), 586-632. https://doi.org/10.5465/annals.2017.0099