Modelling HPM as a PSM, using HPM
I conclude my book on Problem Structuring with some comments on a processual turn in Operational Research (Yearworth, 2025) and specifically comment
“In modelling the world processually we can also model our interventions within the same model … Or put more simply, problematic situations are processes as are the means of intervention.” (p. 270).
Modelling our interventions specifically requires the possibility of representing our use of a problem structuring method as a model. Checkland and Poulter described the process of using Soft Systems Methodology (SSM) in the activity system ‘language’ of SSM itself (Checkland & Poulter, 2006, p. 194; Yearworth, 2025, p. 78). Checkland and Scholes went further and modelled the system to use SSM in the same purposeful activity system language i.e., the ongoing reflective practice of using SSM in client engagements (Checkland & Scholes, 1990, p. 294).
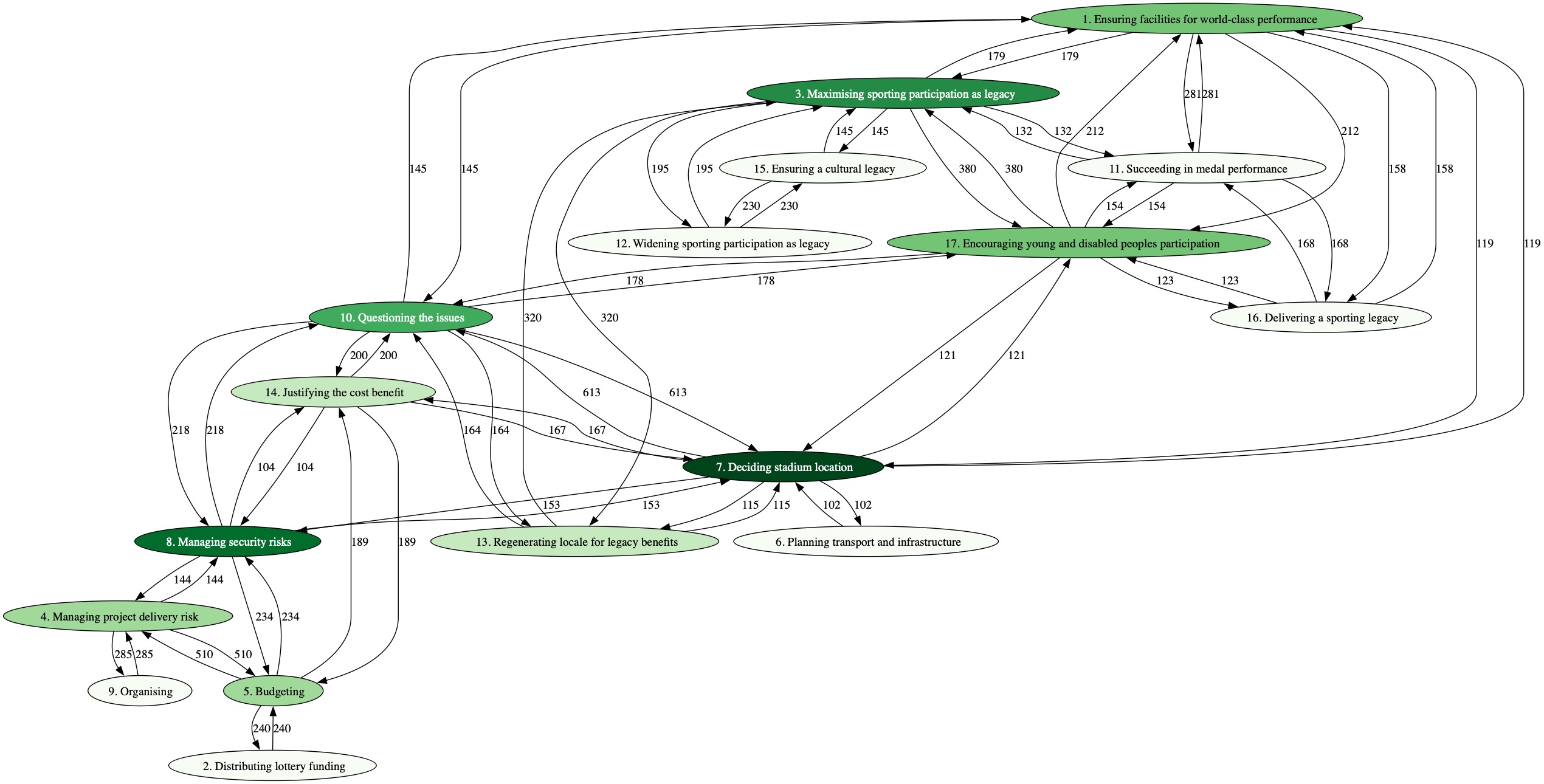
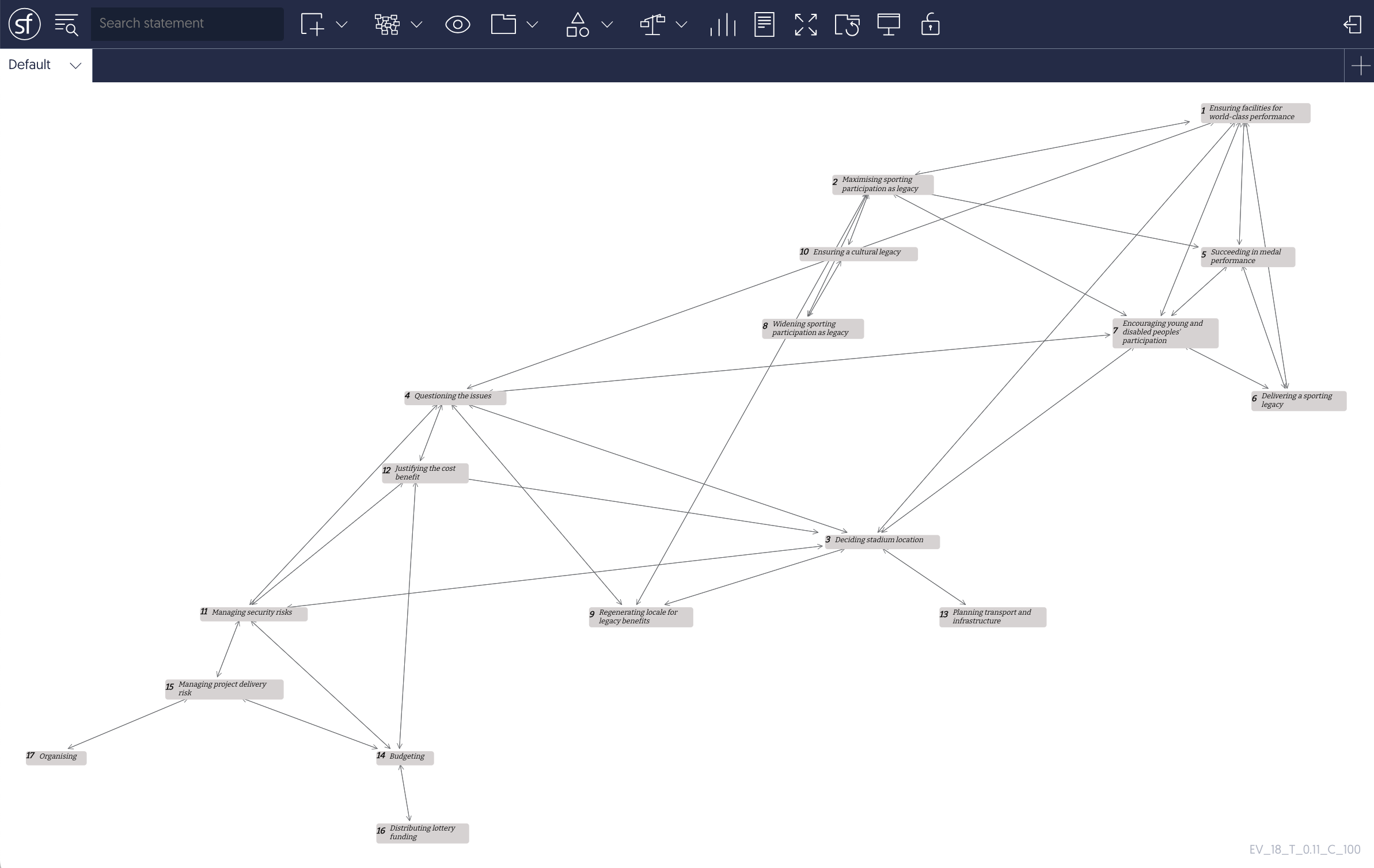
The same approach has been used for describing the use of Hierarchical Process Models (HPM) for problem structuring. This was first manifest in the STEEP Project as means of self-evaluation of how well the methodology was performing, making use of the Italian Flag as a means of capturing judgement of process performance (Yearworth et al., 2015, p. 9). In the Healthy Resilient Cities project (Yearworth, 2015), we started to model the process of using the PSM within the model of the problematic situation itself (Yearworth, 2025, p. 173) i.e., the process <Improving the resilience of healthcare provisioning in Bristol…> contained within it the process <Using problem structuring>. Further work on exploiting the Italian Flag for capturing judgements of process performance in the use of a PSM was explored in depth by Lowe, Espinosa and Yearworth (2020).
The development of HPM as a PSM is described fully in Chapters 9 and 10 of my book. However, the work of modelling HPM as a PSM using HPM itself that was started in the STEEP project is still ongoing. The following shows its current incarnation in Strategyfinder.
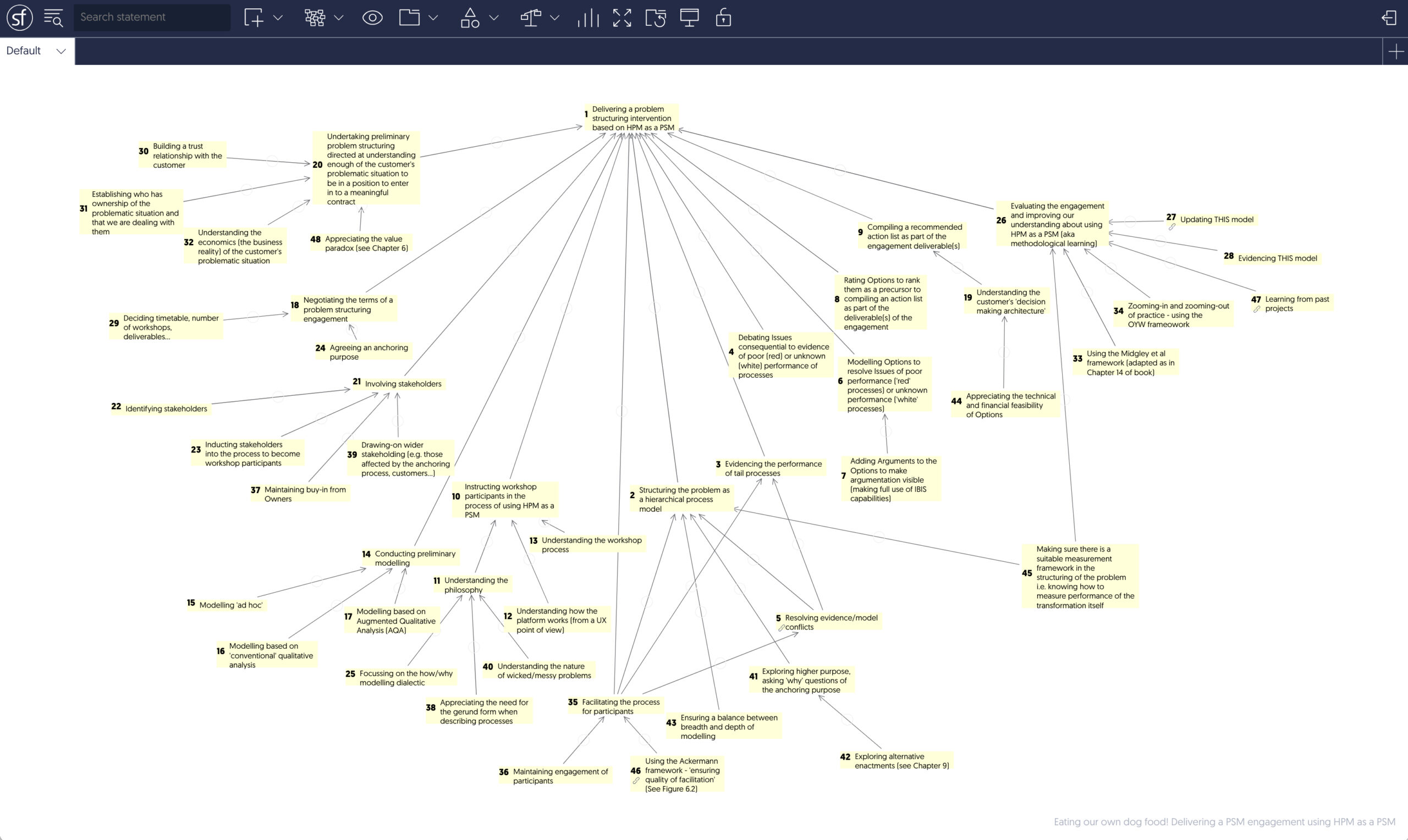
Note that methodological learning, an essential element of using a PSM, is reflected in the model at Process #26 <Evaluating the engagement and improving our understanding …> and the processes it contains. The model also references other models that could be incorporated as enhancements, for example using the framework for improving facilitation developed by Ackermann (1996, p. 95), which has been interpreted in my book as another process model (Yearworth, 2025, p. 108). This illustrates the property that all HPM are composable according to their necessity and sufficiency for the success of the process that acts as the anchor for incorporation.
Ackermann, F. (1996). Participants’ perceptions on the role of facilitators using group decision support systems. Group Decision and Negotiation, 5(1), 93-112. https://doi.org/10.1007/BF02404178
Checkland, P., & Poulter, J. (2006). Learning for action : a short definitive account of soft systems methodology, and its use for practitioner, teachers and students. John Wiley & Sons: Chichester.
Checkland, P., & Scholes, J. (1990). Soft systems methodology in action. John Wiley & Sons: Chichester.
Lowe, D., Espinosa, A., & Yearworth, M. (2020). Constitutive rules for guiding the use of the viable system model: Reflections on practice. European Journal of Operational Research, 287(3), 1014-1035. https://doi.org/10.1016/j.ejor.2020.05.030
Yearworth, M. (2015). Healthy Resilient Cities: Building a Business Case for Adaption (NERC NE/N007638/1)[Grant]. Bristol. http://gotw.nerc.ac.uk/list_full.asp?pcode=NE%2FN007638%2F1
Yearworth, M. (2025). Problem Structuring: Methodology in Practice (1st ed.). John Wiley & Sons, Inc.: Hoboken. https://doi.org/10.1002/9781119744856
Yearworth, M., Schien, D., Burger, K., Shabajee, P., & Freeman, R. (2015). STEEP Project Deliverable D2.1(R2) – Energy Master Plan Process Modelling. STEEP PROJECT (314277) – Systems Thinking for Comprehensive City Efficient Energy Planning, pp78. Retrieved 26th January 2023, from https://www.grounded.systems/wp-content/uploads/2023/01/01_STEEP_D2.1_Energy_Master_Plan_process_model_update_M24_DEF_sent.pdf